
Environment Setup
安装依赖包
- llama-cpp-python:大模型 Llama 3.1 的运行引擎,并下载支持 NVIDIA CUDA 12.2 的版本
- 网页爬取
- googlesearch-python:搜索入口,给关键词,会返回 Google 搜索结果的 URL 链接列表
- requests-html:网页下载,负责根据 URL 把网页的整个 HTML 源代码 下载到本地。支持异步(Async),速度快。
- bs4 (BeautifulSoup4):解析 HTML,从源码中提取纯文本,去掉无用的标签
- charset-normalizer:编码识别,自动识别网页是 UTF-8 还是 GBK 编码,防止抓取下来的内容变成乱码(尤其是中文网页)。
- lxml_html_clean:安全清洗,专门用来清理 HTML 中恶意或冗余的内容,确保喂给 AI 的文本是干净的。
python3 -m pip install --no-cache-dir llama-cpp-python==0.3.4 --extra-index-url https://abetlen.github.io/llama-cpp-python/whl/cu122
python3 -m pip install googlesearch-python bs4 charset-normalizer requests-html lxml_html_clean
下载LLaMA 3.1 8B量化版本的权重( around 8GB.)
下载数据集
from pathlib import Path
if not Path('./Meta-Llama-3.1-8B-Instruct-Q8_0.gguf').exists():
!wget https://huggingface.co/bartowski/Meta-Llama-3.1-8B-Instruct-GGUF/resolve/main/Meta-Llama-3.1-8B-Instruct-Q8_0.gguf
if not Path('./public.txt').exists():
!wget https://www.csie.ntu.edu.tw/~ulin/public.txt
if not Path('./private.txt').exists():
!wget https://www.csie.ntu.edu.tw/~ulin/private.txt
测试GPU是否可用
import torch
if not torch.cuda.is_available():
raise Exception('You are not using the GPU runtime. Change it first or you will suffer from the super slow inference speed!')
else:
print('You are good to go!')
Prepare the LLM and LLM utility function
首先将LLM的权重注入GPU
提供输入LLM,获取LLM返回信息的工具函数: generate_response()
可以忽略"llama_new_context_with_model: n_ctx_per_seq (16384) < n_ctx_train (131072) -- the full capacity of the model will not be utilized" 警告.
from llama_cpp import Llama
# 将模型参数注入GPU
llama3 = Llama(
"./Meta-Llama-3.1-8B-Instruct-Q8_0.gguf",
verbose=False,
n_gpu_layers=-1,
n_ctx=16384, # This argument is how many tokens the model can take. The longer the better, but it will consume more memory. 16384 is a proper value for a GPU with 16GB VRAM.
)
def generate_response(_model: Llama, _messages: str) -> str:
'''
This function will inference the model with given messages.
'''
_output = _model.create_chat_completion(
_messages,
stop=["<|eot_id|>", "<|end_of_text|>"],
max_tokens=512, # This argument is how many tokens the model can generate.
temperature=0, # This argument is the randomness of the model. 0 means no randomness. You will get the same result with the same input every time. You can try to set it to different values.
repeat_penalty=2.0,
)["choices"][0]["message"]["content"]
return _output
Search Tool
实现一个搜索工具,执行用关键词进行Google搜索,搜索相关 web pages
from typing import List
from googlesearch import search as _search
from bs4 import BeautifulSoup
from charset_normalizer import detect
import asyncio
from requests_html import AsyncHTMLSession
import urllib3
urllib3.disable_warnings()
async def worker(s:AsyncHTMLSession, url:str):
try:
header_response = await asyncio.wait_for(s.head(url, verify=False), timeout=10)
if 'text/html' not in header_response.headers.get('Content-Type', ''):
return None
r = await asyncio.wait_for(s.get(url, verify=False), timeout=10)
return r.text
except:
return None
async def get_htmls(urls):
session = AsyncHTMLSession()
tasks = (worker(session, url) for url in urls)
return await asyncio.gather(*tasks)
async def search(keyword: str, n_results: int=3) -> List[str]:
'''
This function will search the keyword and return the text content in the first n_results web pages.
Warning: You may suffer from HTTP 429 errors if you search too many times in a period of time. This is unavoidable and you should take your own risk if you want to try search more results at once.
The rate limit is not explicitly announced by Google, hence there's not much we can do except for changing the IP or wait until Google unban you (we don't know how long the penalty will last either).
'''
keyword = keyword[:100]
# First, search the keyword and get the results. Also, get 2 times more results in case some of them are invalid.
results = list(_search(keyword, n_results * 2, lang="zh", unique=True))
# Then, get the HTML from the results. Also, the helper function will filter out the non-HTML urls.
results = await get_htmls(results)
# Filter out the None values.
results = [x for x in results if x is not None]
# Parse the HTML.
results = [BeautifulSoup(x, 'html.parser') for x in results]
# Get the text from the HTML and remove the spaces. Also, filter out the non-utf-8 encoding.
results = [''.join(x.get_text().split()) for x in results if detect(x.encode()).get('encoding') == 'utf-8']
# Return the first n results.
return results[:n_results]
Agents
- Attributes:
- role_description
- task_description
- llm: Just an indicator of the LLM model used by the agent.
- Method:
- inference
class LLMAgent():
# 定义Agent角色
def __init__(self, role_description: str, task_description: str, llm:str="bartowski/Meta-Llama-3.1-8B-Instruct-GGUF"):
self.role_description = role_description
self.task_description = task_description
self.llm = llm # LLM indicates which LLM backend this agent is using.
# 推理,提供输入信息获取回复的接口
def inference(self, message:str) -> str:
if self.llm == 'bartowski/Meta-Llama-3.1-8B-Instruct-GGUF': # If using the default one.
# TODO: Design the system prompt and user prompt here.
# Format the messsages first.
messages = [
{"role": "system", "content": f"{self.role_description}"},
{"role": "user", "content": f"{self.task_description}\n{message}"}
]
return generate_response(llama3, messages)
else:
# TODO: If you want to use LLMs other than the given one, please implement the inference part on your own.
messages = [
{"role": "system", "content": f"{self.role_description}"},
{"role": "user", "content": f"{self.task_description}\n{message}"}
]
return generate_response(self.llm, messages)
TODO 1: Design the role description and task description for each agent.
# TODO: Design the role and task description for each agent.
# This agent may help you filter out the irrelevant parts in question descriptions.
question_extraction_agent = LLMAgent(
role_description="你是LLaMA-3.1-8B,是用来提取问题中的关键问题的 AI。并且提取出关键问题的内容总转为简体中文形式。",
task_description="请提取出问题中的关键问题方便进行精准问答",
)
# This agent may help you extract the keywords in a question so that the search tool can find more accurate results.
keyword_extraction_agent = LLMAgent(
role_description="你是LLaMA-3.1-8B,是用来提取文本关键词的 AI。并且提取出关键词内容总转为简体中文形式。",
task_description="请提取出文本中的关键词方便进行搜索信息",
)
# This agent is the core component that answers the question.
qa_agent = LLMAgent(
role_description="你是LLaMA-3.1-8B,是用来回答问题的 AI。使用中文时只会使用简体中文来回答问题。",
task_description="请回答以下问題:",
)
RAG pipeline
TODO 2: Implement the RAG pipeline.
还有别的想法(e.g. classifying the questions based on their lengths, determining if the question need a search or not, reconfirm the answer before returning it to the user……) 没有显示在下面,可以自由实现自己的想法。
-
Naive approach (simple baseline)
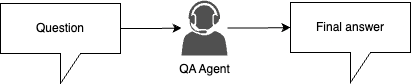
-
Naive RAG approach (medium baseline)
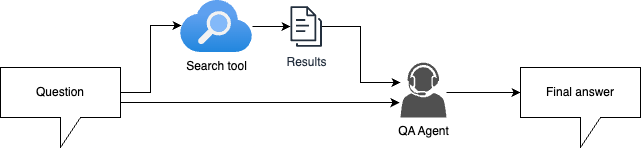
-
RAG with agents (strong baseline)
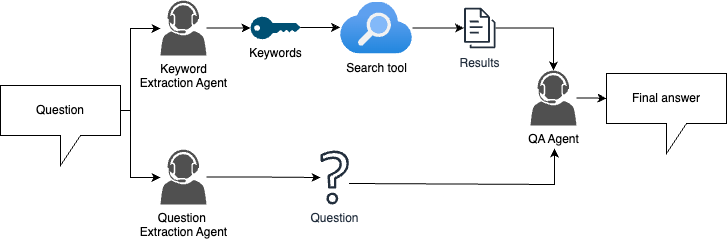
async def pipeline(question: str) -> str:
# TODO: Implement your pipeline.
# You may want to get the final results through multiple inferences.
# Just a quick reminder, make sure your input length is within the limit of the model context window (16384 tokens), you may want to truncate some excessive texts.
key_question = question_extraction_agent.inference(question) # 提取问题的关键问题
keywords = keyword_extraction_agent.inference(question) # 提取关键词用于搜索
# 搜索相关内容,不过估计实验的时候会触发Google的反爬虫机制
try:
search_results = await search(keywords, n_results=3)
print(f"找到 {len(search_results)} 个搜索结果")
except Exception as e:
print(f"搜索失败: {e}") search_results = []
# 将搜索结果整合起来
if search_results:
context = f"问题:{clean_question}\n\n相关搜索结果:\n"
for i, result in enumerate(search_results, 1): # 1表示计数器从1开始,所以i从1始
context += f"{i}. {result[:1000]}\n" # 取前1000字符
if len(context) > 12000: # 上下文窗口大小16384tokens,留给system prompt空间
context = context[:12000] + "...(内容已截断)"
break
else: context = clean_question
# 将上下文和问题拼接成输入消息
input_message = f"Context:\n{context}\n\nQuestion: {key_question}"
return qa_agent.inference(input_message)
为了保证信息尽可能保留且多样,采取每个都取点,因为LLM有能力处理截断句子,所以超了后截断,而不是判断会超后不添加。
可以先判断下是否Google封IP了
import googlesearch
# 看看这一行能不能打印出链接
print(list(googlesearch.search("Python tutorial", num_results=3)))
Answer the questions using your pipeline!
from pathlib import Path
# Fill in your student ID first,只是给结果文件命名,这里我们随便填个数字就行
STUDENT_ID = ""
STUDENT_ID = STUDENT_ID.lower()
with open('./public.txt', 'r') as input_f:
questions = input_f.readlines()
questions = [l.strip().split(',')[0] for l in questions]
for id, question in enumerate(questions, 1):
if Path(f"./{STUDENT_ID}_{id}.txt").exists():
continue
answer = await pipeline(question) # 核心调用
answer = answer.replace('\n',' ')
print(id, answer) # 输出回答
with open(f'./{STUDENT_ID}_{id}.txt', 'w') as output_f:
print(answer, file=output_f) # 写文件
with open('./private.txt', 'r') as input_f:
questions = input_f.readlines()
for id, question in enumerate(questions, 31):
if Path(f"./{STUDENT_ID}_{id}.txt").exists():
continue
answer = await pipeline(question) # 核心调用
answer = answer.replace('\n',' ')
print(id, answer) # 输出回答
with open(f'./{STUDENT_ID}_{id}.txt', 'a') as output_f:
print(answer, file=output_f) # 写文件
# Combine the results into one file.
with open(f'./{STUDENT_ID}.txt', 'w') as output_f:
for id in range(1,91):
with open(f'./{STUDENT_ID}_{id}.txt', 'r') as input_f:
answer = input_f.readline().strip()
print(answer, file=output_f)


