参考资料:
- Mem0 – The Memory Layer for your AI Apps
- mem0ai/mem0 | DeepWiki
- code:mem0ai/mem0: Universal memory layer for AI Agents

Overview
添加记忆:让LLM提取facts,然后依此搜索记忆让LLM决定怎样更新记忆,默认用语义向量,可选添加知识图谱(自然要让LLM提取实体和生成关系)
检索记忆:将查询转为向量进行语义向量搜索,可选添加图搜索,合并结果
思路上mem0实现memory与其他相比没有突出的亮点,但是工程化落地成熟,不像有些学术项目bug特多
- 支持多维租户管理:支持 User(用户)、Session(会话) 和 Agent(智能体) 三个层级的隔离与互通
- 将操作日志记录下来
- 分层清晰,模块专一,LLM做专一的事情,避免注意力偏移(顾此失彼)
用户对话 (Conversation)
│
▼
┌───────────────────────────────────────────────┐
│ Memory 类 (mem0/memory/main.py) │
│ │
│ ┌─────────────┐ ┌────────────────────┐ │
│ │ LLM 层 │ │ Embedding 层 │ │
│ │ (事实提取) │ │ (向量化 / 语义搜索) │ │
│ └─────────────┘ └────────────────────┘ │
│ │
│ ┌─────────────────────────────────────────┐ │
│ │ 存储层 (Storage Layer) │ │
│ │ ┌────────────┐ ┌───────────┐ ┌───────┐ │ │
│ │ │Vector Store│ │Graph Store│ │ SQLite│ │ │
│ │ │ (语义向量) │ │ (知识图谱) │ │ (历史) │ │ │
│ │ └────────────┘ └───────────┘ └───────┘ │ │
│ └─────────────────────────────────────────┘ │
└───────────────────────────────────────────────┘
│
▼
个性化 AI 应用 (Personalized AI Application)
流程
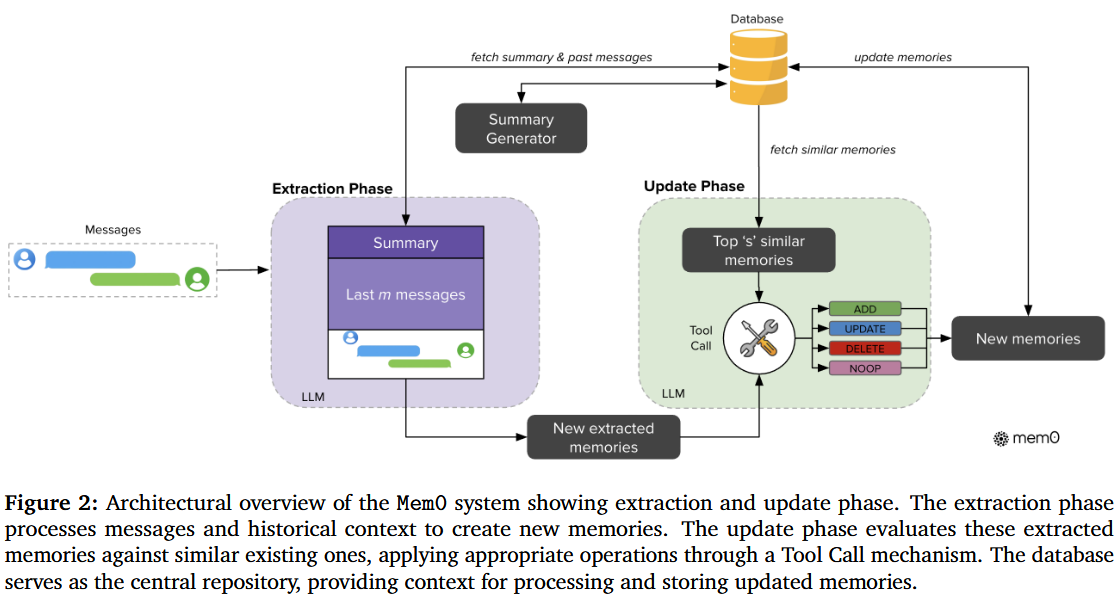
(参照下面写的流程看这张图会很清晰)
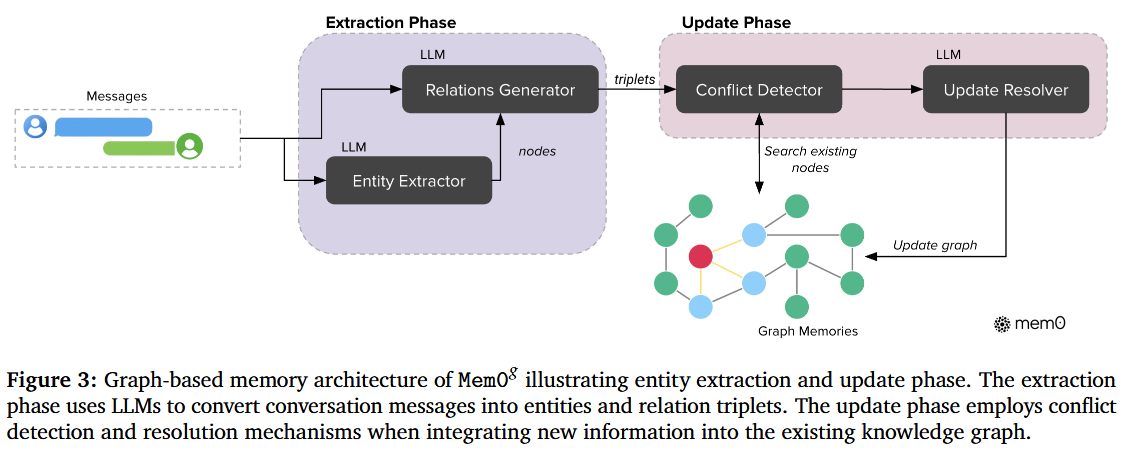
(基于知识图谱实现的Mem0)
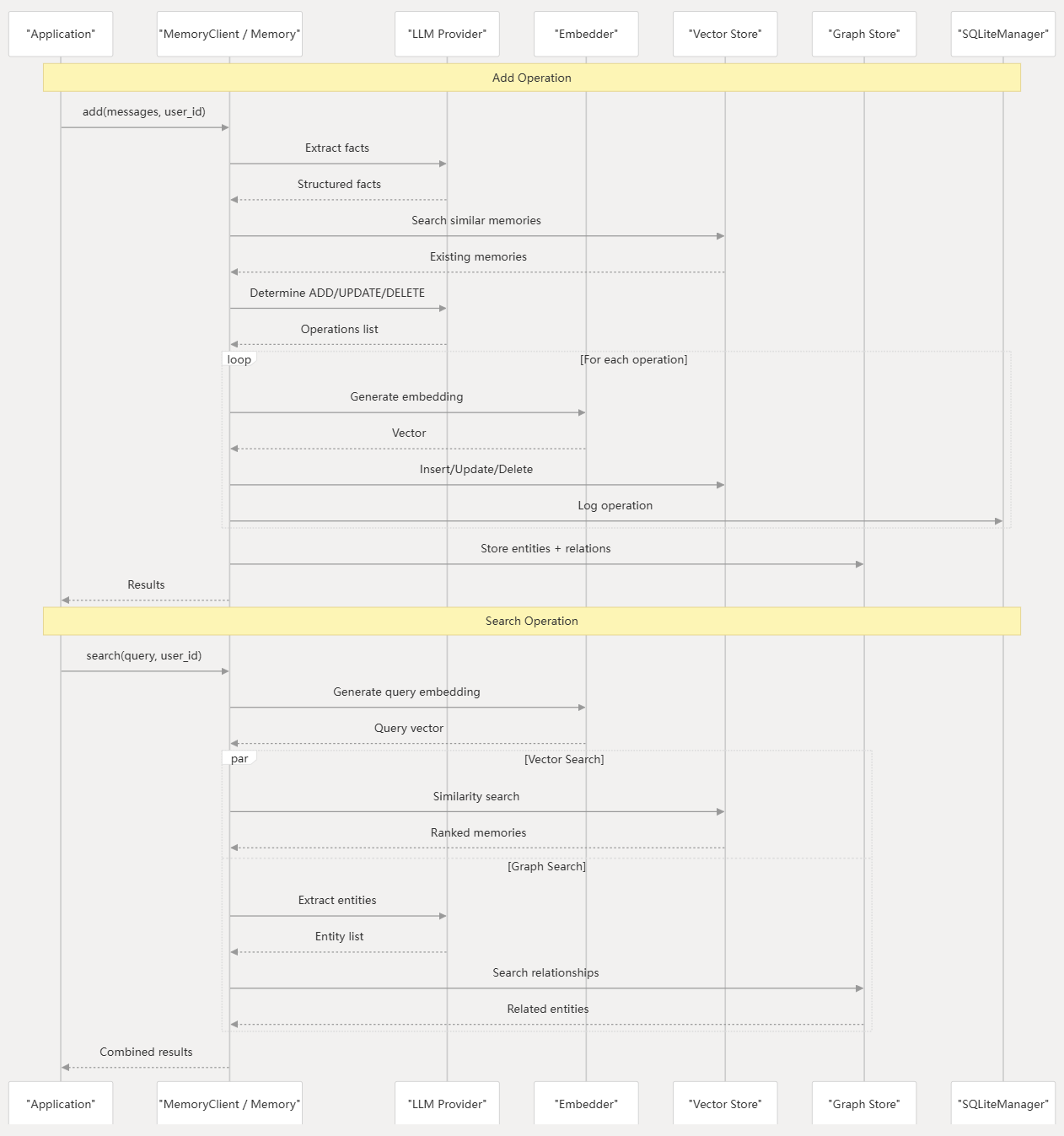
mem0将所有操作集成了2个操作:add和search
应用层调用MemoryClient(云端)/Memory(本地)
- add:
- 到
LLM Provider让LLM提取facts并返回结构化的facts- 这里还设定了
Summary Generator的LLM,负责将Vector Store过往
- 这里还设定了
- 到
Vecotr Store搜索相似的记忆,返回现有记忆 - 到
LLM Provider让LLM对于每个fact决定操作:ADD、UPDATE、DELETE,返回操作列表 - 遍历操作列表执行:
- 到
Embedder向量化后返回 - 对
Vector Store更新,进行操作:Insert、Update、Delete - 到
Graph Store存储实体和关系(如果开启)(与写Vector Store同步) - 记录操作日志于
SQLiteManager
- 到
- 返回结果到应用层
- 到
- search:
Embedder将查询转为向量并返回- 向量搜索
Vector Store执行相似度搜索,返回排名后的记忆
- 图搜索(可选)
LLM Provider从查询向量中提取实体并返回实体列表- 根据实体列表到
Graph Store搜索关系,返回相关实体
- 对两种结果一起使用
Reranker(可选) - 合并两种搜索的结果并返回
数据流
Memories partition by four session identifiers:
| Identifier | Scope | Use Case |
|---|---|---|
user_id |
Long-term user context | Personal preferences, account settings |
agent_id |
Agent-specific context | Agent behavior, tools, workflows |
app_id |
Application-level context | Multi-tenant isolation |
run_id |
Ephemeral session context | Temporary task state, debug sessions |
代码
- 原代码:mem0ai/mem0: Universal memory layer for AI Agents
- 个人整理代码:Echo-Kang-hub/mem0: Universal memory layer for AI Agents
OSS Deployment
- Core:
Memoryclass at mem0/memory/main.py - Configuration:
MemoryConfigwith provider selection - Default vector store: Qdrant at
/tmp/qdrant - History tracking: SQLite at
~/.mem0/history.db - Requires: Python 3.9+ per pyproject.toml15

项目目录结构
mem0/
├── __init__.py # 导出 Memory, AsyncMemory, MemoryClient
├── exceptions.py # 自定义异常类(ValidationError, LLMError 等)
│
├── memory/ # 核心 Memory 实现
│ ├── main.py # ★ Memory 类主文件(add/search/get/update/delete)
│ ├── base.py # ABC 抽象基类(定义接口规范)
│ ├── graph_memory.py # Graph Memory(基于 Neo4j 的知识图谱记忆)
│ ├── storage.py # SQLiteManager(历史变更追踪)
│ ├── utils.py # 工具函数(消息解析、Prompt 构建、JSON 提取)
│ ├── setup.py # 初始化配置目录
│ └── telemetry.py # 使用遥测(匿名统计)
│
├── configs/
│ ├── base.py # MemoryConfig、MemoryItem Pydantic 模型
│ ├── prompts.py # ★ 核心 Prompt(事实提取、记忆决策、过程记忆)
│ └── enums.py # MemoryType 枚举
│
├── llms/ # LLM 适配层(Provider Adapters)
│ ├── openai.py # OpenAI / Azure OpenAI
│ ├── anthropic.py # Anthropic Claude
│ ├── google.py # Google Gemini
│ ├── ollama.py # 本地 Ollama
│ └── ... # 20+ LLM 支持
│
├── embeddings/ # Embedding 模型适配层
│ ├── openai.py # text-embedding-ada-002 等
│ ├── huggingface.py # 本地 HuggingFace 模型
│ └── ... # 10+ Embedding 支持
│
├── vector_stores/ # Vector Store 适配层
│ ├── qdrant.py # 默认:本地 Qdrant
│ ├── faiss.py # Facebook FAISS(纯本地)
│ ├── pinecone.py # Pinecone(云端)
│ └── ... # 20+ Vector Store 支持
│
├── graphs/ # Graph Store 配置与工具
│ ├── configs.py # GraphStoreConfig
│ ├── tools.py # LLM Function Calling 工具定义
│ └── utils.py # Cypher 查询构建、关系提取 Prompt
│
├── reranker/ # Reranker 精排层(可选)
│ ├── base.py
│ └── ...
│
├── client/ # Mem0 云平台 API Client
│ └── main.py # MemoryClient(调用 Mem0 托管服务)
│
└── utils/
└── factory.py # ★ 工厂类(LlmFactory, EmbedderFactory, VectorStoreFactory 等)
mem0-ts/ # TypeScript SDK(与 Python SDK 功能对等)
openmemory/ # OpenMemory —— 自托管记忆管理 UI
server/ # FastAPI REST API 服务端
embedchain/ # EmbedChain(RAG 框架,已并入 Mem0 生态)
evaluation/ # 性能评测脚本(LOCOMO 基准)
examples/ # 示例代码(多 Agent、多模态、Chrome 扩展等)
接下来我们按以下逻辑分析
- 存储层
- 支持的memory类型
- 核心操作的add实现的代码逻辑
- 核心操作的search实现的代码逻辑
- Prompt设计:提取事实的prompt、决定对记忆的操作的prompt
- 额外可选的知识图谱的实现(可与向量路径同步)
一、三层存储体系
Mem0 采用三层互补的存储架构,各司其职:
1. Vector Store(向量数据库)—— 语义长期记忆
核心文件: mem0/vector_stores/ 目录,支持 20+ 种向量数据库。
默认使用本地 Qdrant,同时支持:
| 类型 | 支持的数据库 |
|---|---|
| 云托管 | Pinecone, Weaviate, Supabase, MongoDB Atlas, Elasticsearch, OpenSearch |
| 本地部署 | Qdrant (本地), FAISS, Chroma, Redis, Milvus |
| 企业级 | Azure AI Search, Databricks, Vertex AI, Neptune Analytics |
所有记忆(Memory)以 (向量, payload) 对的形式存储,payload 包含:
{
"data": "用户喜欢意大利菜",
"hash": "sha256_of_data",
"user_id": "alice",
"created_at": "2026-02-26T10:00:00",
"updated_at": "2026-02-26T10:00:00"
}
2. Graph Store(图数据库)—— 关系知识图谱
核心文件: mem0/memory/graph_memory.py、mem0/graphs/
可选启用,基于 Neo4j 构建实体关系三元组(Entity-Relation Triples):
(用户 Alice) --[喜欢]--> (意大利菜)
(用户 Alice) --[住在]--> (上海)
(用户 Alice) --[工作]--> (软件工程师)
通过 LLM 自动从对话中抽取实体(Entity)和关系(Relation),支持复杂语义查询。
3. SQLite History DB —— 操作历史追踪
核心文件: mem0/memory/storage.py
记录每条记忆的完整变更历史(ADD / UPDATE / DELETE),支持通过 memory.history(memory_id) 回溯。
memory_id | old_memory | new_memory | event | timestamp
----------|------------|------------|---------|----------
uuid-001 | None | "爱好跑步" | ADD | 2026-01-01
uuid-001 | "爱好跑步" | "爱好马拉松"| UPDATE | 2026-02-01
二、Memory 类型
核心文件: mem0/configs/enums.py、mem0/memory/main.py
Mem0 支持三种内存类型(Memory Types):
| 类型 | 英文名 | 触发条件 | 用途 |
|---|---|---|---|
| 语义记忆 | Semantic Memory | 默认,用户对话 | 存储事实性偏好与信息 |
| 情节记忆 | Episodic Memory | Agent + 用户对话 | 记录对话事件与交互历史 |
| 过程记忆 | Procedural Memory | memory_type="procedural_memory" |
Agent 的任务执行步骤与计划摘要 |
# 语义/情节记忆(默认)
memory.add(messages, user_id="alice")
# 过程记忆(Procedural Memory)—— 适用于 Agent 任务追踪
memory.add(agent_steps, agent_id="my_agent", memory_type="procedural_memory")
三、add() 写入流程
核心文件: mem0/memory/main.py → Memory.add() → Memory._add_to_vector_store()
整个写入流程分为 5 个步骤,核心是利用 LLM 实现智能的增量式记忆管理:
输入消息 (messages)
│
▼ 步骤 1:消息预处理
parse_messages() ← 将 role/content 列表拼接为纯文本
│
▼ 步骤 2:事实提取 (Fact Extraction)
LLM.generate_response()
Prompt: USER_MEMORY_EXTRACTION_PROMPT / AGENT_MEMORY_EXTRACTION_PROMPT
输出: {"facts": ["用户叫 Alice", "喜欢跑步", "住在上海"]}
│
▼ 步骤 3:向量相似度检索 (Similarity Search)
for each fact:
embedding = EmbeddingModel.embed(fact) ← 将每条事实向量化
old_memories = VectorStore.search(embedding) ← 检索相似的旧记忆(Top-5)
│
▼ 步骤 4:记忆决策 (Memory Decision via LLM)
LLM.generate_response()
Prompt: DEFAULT_UPDATE_MEMORY_PROMPT
输入: [旧记忆列表] + [新事实列表]
输出: {"memory": [
{"id": "0", "text": "喜欢马拉松", "event": "UPDATE", "old_memory": "喜欢跑步"},
{"id": "new", "text": "住在上海", "event": "ADD"},
{"id": "2", "text": "...", "event": "NONE"}
]}
│
▼ 步骤 5:执行写入 (Execute Operations)
ADD → VectorStore.insert() + SQLiteManager.add_history()
UPDATE → VectorStore.update() + SQLiteManager.add_history()
DELETE → VectorStore.delete() + SQLiteManager.add_history()
NONE → 无操作(或仅更新 session ID)
关键设计:并发执行 Vector Store 写入与 Graph Store 写入
# mem0/memory/main.py
with concurrent.futures.ThreadPoolExecutor() as executor:
future1 = executor.submit(self._add_to_vector_store, messages, metadata, filters, infer)
future2 = executor.submit(self._add_to_graph, messages, filters)
concurrent.futures.wait([future1, future2])
四、search() 检索流程
核心文件: mem0/memory/main.py → Memory.search()
查询语句 (query string)
│
▼ 向量化
embedding = EmbeddingModel.embed(query, "search")
│
▼ 向量相似度检索
results = VectorStore.search(
query=query,
vectors=embedding,
limit=limit,
filters={"user_id": "alice"} ← 按会话 ID 隔离不同用户的记忆
)
│
▼ 可选:Reranker 精排(需配置)
if self.reranker:
results = Reranker.rerank(query, results)
│
▼ 可选:相似度阈值过滤(threshold)
results = [r for r in results if r.score >= threshold]
│
▼ 并发检索 Graph Store(如果启用)
graph_results = GraphStore.search(query, filters)
│
▼ 返回
{"results": [...memories...], "relations": [...graph triples...]}
会话隔离(Session Isolation)机制:
Mem0 通过三种**会话 ID(Session ID)**实现多用户、多 Agent、多运行的记忆隔离:
| 参数 | 含义 | 典型用途 |
|---|---|---|
user_id |
用户标识符 | 个人记忆,跨会话持久 |
agent_id |
Agent 标识符 | Agent 的专属行为记忆 |
run_id |
运行标识符 | 单次任务的临时上下文 |
三者可组合使用,至少提供一个。
五、LLM Prompt 设计
核心文件: mem0/configs/prompts.py
Mem0 的智能性主要来自两个关键 Prompt:
Prompt 1:事实提取(Fact Extraction)
有两个版本,根据场景自动切换:
USER_MEMORY_EXTRACTION_PROMPT:从用户消息中提取事实,忽略 assistant 消息AGENT_MEMORY_EXTRACTION_PROMPT:从 assistant 消息中提取 Agent 的行为特征,忽略用户消息
切换逻辑(_should_use_agent_memory_extraction()):
# 当同时满足以下两个条件时,使用 Agent 提取模式:
# 1. 传入了 agent_id
# 2. messages 中包含 assistant 角色的消息
return has_agent_id and has_assistant_messages
Prompt 输出格式(JSON):
{"facts": ["名字是 Alice", "喜欢意大利菜", "住在上海"]}
Prompt 2:记忆决策(Memory Decision)
DEFAULT_UPDATE_MEMORY_PROMPT 负责对比新旧记忆,决定增删改:
旧记忆:
[{"id": "0", "text": "喜欢奶酪披萨"}]
新事实:
["喜欢鸡肉披萨"]
决策输出:
{"memory": [
{"id": "0", "text": "喜欢奶酪和鸡肉披萨", "event": "UPDATE", "old_memory": "喜欢奶酪披萨"}
]}
支持四种操作(Operations):
| 事件(Event) | 触发条件 | 说明 |
|---|---|---|
ADD |
新事实在旧记忆中不存在 | 插入新记忆 |
UPDATE |
新事实与旧记忆内容不同但相关 | 合并更新,保留最多信息 |
DELETE |
新事实与旧记忆相矛盾 | 删除过时记忆 |
NONE |
信息已存在或不相关 | 不做修改 |
注意: 为防止 LLM 产生 UUID 幻觉(UUID Hallucination),系统在调用 LLM 前将真实 UUID 临时映射为整数索引(
temp_uuid_mapping),LLM 返回后再还原。
六、Graph Memory 知识图谱
核心文件: mem0/memory/graph_memory.py、mem0/graphs/
当启用 graph_store 配置时,Graph Memory 并发执行,通过 LLM 抽取实体与关系:
输入文本
│
▼ 实体识别 (Entity Extraction via LLM)
{"entities": ["Alice", "上海", "软件工程师"]}
│
▼ 关系建立 (Relation Establishment via LLM)
{"relations": [
{"source": "Alice", "relationship": "住在", "destination": "上海"},
{"source": "Alice", "relationship": "职业", "destination": "软件工程师"}
]}
│
▼ 冲突检测与删除 (Conflict Detection)
搜索图数据库中已有节点,对矛盾关系执行 LLM 决策后删除
│
▼ 写入 Neo4j(Cypher 查询)
MERGE (n:__Entity__ {name: "Alice", user_id: "alice"})
MERGE (m:__Entity__ {name: "上海", user_id: "alice"})
MERGE (n)-[:住在]->(m)


