
速览
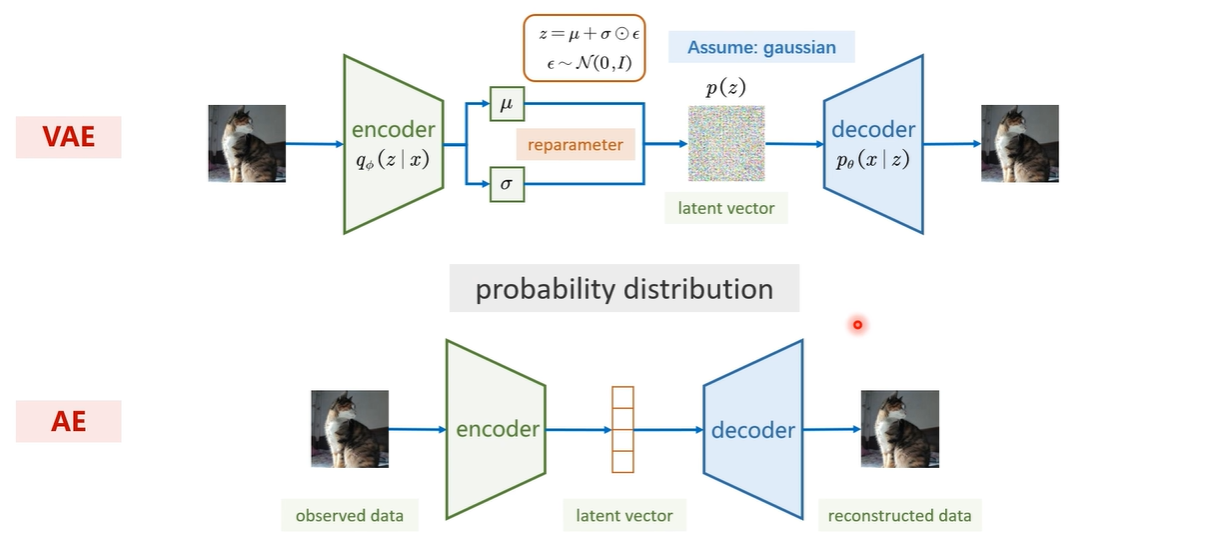
假设隐空间符合高斯分布
VAE和AE就差别在概率分布:高斯分布
隐向量(latent vector)
隐空间
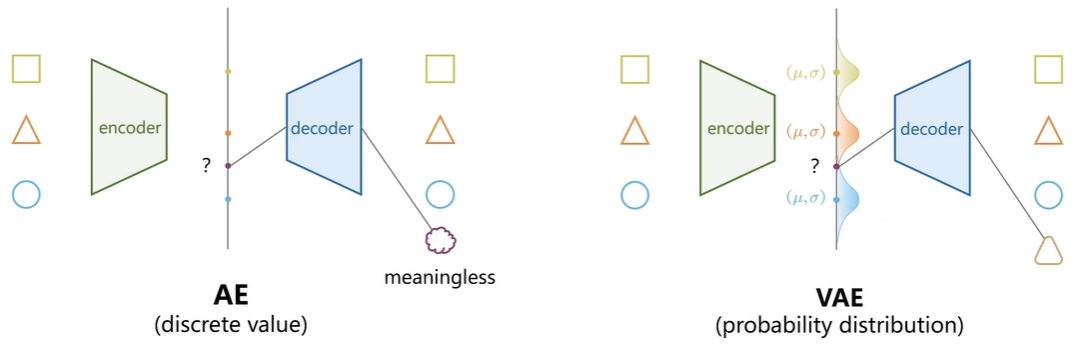
AE的隐向量是离散的(隐空间离散),之间的点是无意义的。
增加概率分布实现隐空间连续,之间的点有意义。
VAE是一种用正则化避免过拟合,并确保隐空间有能够进行生成的优良表征。
方法
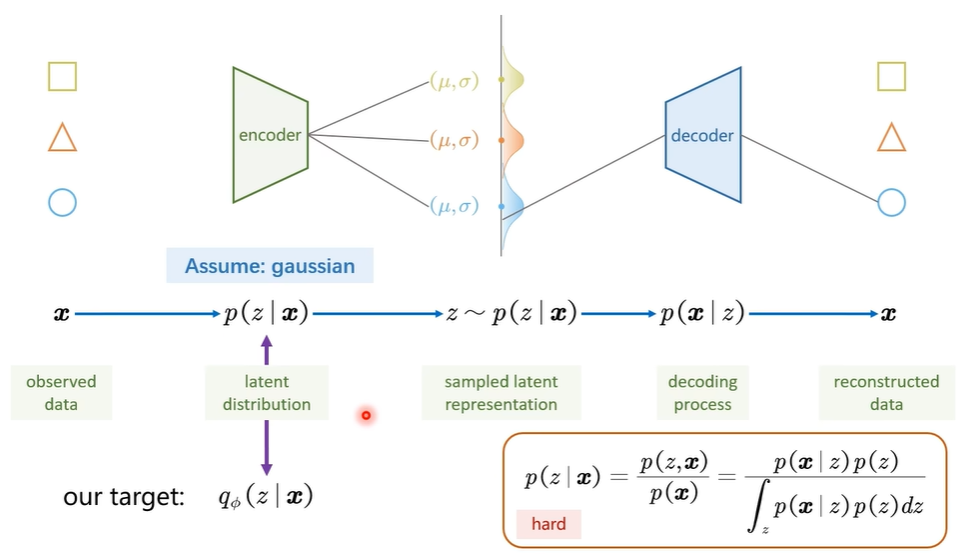
假设隐空间的点服从高斯分布,即p(z)符合高斯分布
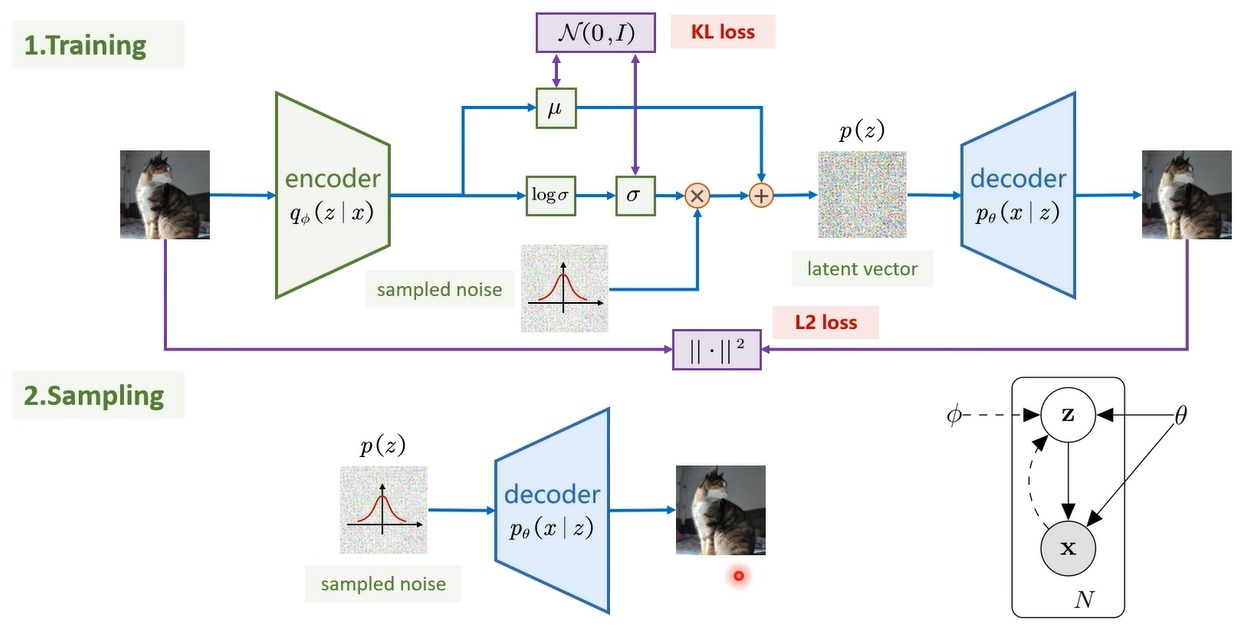
训练的过程:有观察图像x,通过编码器获得隐空间z,从隐空间z中采样隐向量,通过解码器获得重建图像x。
训练中我们就认为
p(z|x)是已知事实x推导背后的隐变量z,属于后验分布;
是先验分布
每一张图像有对应得图像分布,所以生成一张图像,我们看其图像分布,比如让猫的概率更大,让其他的概率更小。
Evidence Lower Bound(ELBO)
KL的角度
可以用KL散度让神经网络拟合后验分布
KL散度,简单来说他就是衡量两个分布之间的距离,值越小两者越相近,值越大两者差距越大
其中
期望的定义$$\mathbb{E}_{x \sim P(x)}[f(x)] = \int P(x)f(x)dx$$
得到:
其中
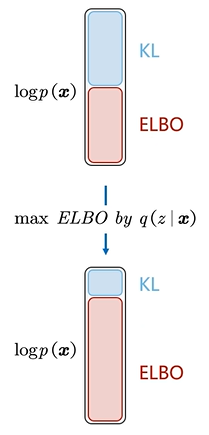
所以目标让ELBO更大
其中
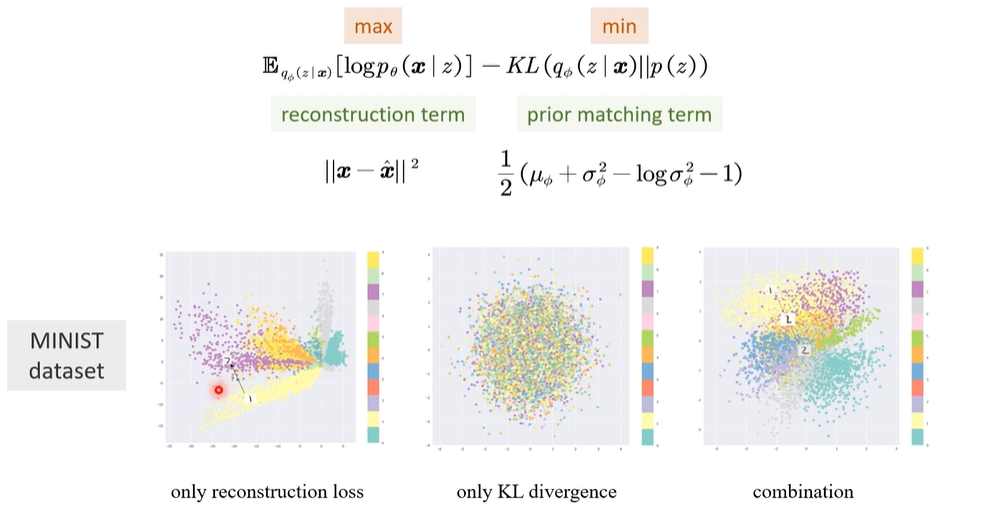
是隐空间z到生成图像x重建,越大越好,认定为reconstruction term 是先验,越小越好,认定为prior matching term
也就是说从神经网络和
reconstruction term就是看原图像和生成图像的效果,用
我们看下
噪声是随机性和不确定性,是确定的值周围的可能
然后推导
所以
让神经网络拟合
这里可以用
因此,prior matching term就可以直接用
总结来说,VAE的优化就是
- reconstruction term的
,L2 Loss - prior matching term的
,
最大似然的角度
一样推出
总结如下图:
下面结果可以说明2个Loss缺一不可,唯有都有,才能紧凑且区分。
为什么Work
图像分布可以由多个高斯分布组合而成,多个高斯分布通过Decoder实现组合,得到图像分布。Encoder完成的就是将图像映射到隐空间的01高斯分布。
局限
第一个是后验概率坍塌。
指后验概率坍塌成先验概率,后验的意义坍塌,当坍塌发生后,不论你输入的是
我们预期一开始让
显然前者是完全可能发生的,尤其是网络倾向于向最方便下降的方向进行。
VAE 的损失函数是两个目标:努力重建图像和让隐空间符合
(KL散度)
为了迅速降低总体的 Loss,Encoder走捷径,不管x输入是什么,都输出均值为 0、方差为 1 的标准高斯分布,即都是01高斯分布,那么我的 KL 散度这一项 Loss 就变成 0,这样下来 ,提取出来的特征 里,不再包含任何关于输入 的有效信息。
第二个是图像映射到的分布是近似01高斯分布但不等于,但是采样(即生成时)是当作01高斯分布采样,这里出现不匹配。
训练时(Autoencoding):输入图片
生成时(Generation):我们没有输入图片了,直接把 Encoder 扔掉。我们假定整个隐空间就是完美的
Stable diffusion就是多次加噪,最终一定映射到01高斯分布。



